Machine Learning - Coursera
I recently finished the “Machine Learning” course from Stanford University on Coursera and I want to share may thoughts and opinions about this. You have to believe me that after you will finish this course you will feel like you want to become a machine learning scientist.
TL;DR
If you don’t want to spent time to read this post you can access the course here Machine Learning and start learning.
Why to take the course
This course is the best way to start learning about machine learning, to fully understand what machine learning is and you can use it efficiently to solve real life problems.
Before taking this course I thought I have an idea of what the machine learning is, I was reading in the past about models, gradient descent and some tools like TensorFlow an so on, but I was wrong, I did’t know anything about. Only after I finished the course I fully understand what machine learning really is and how powerful can be.
I will highlight some of the things that I learned from this course.
What is machine learning
Tom Mitchell provides a modern definition of the machine learning: “A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”
For example for a spam classifier:
T = Classifying email as spam or not spam
E = Watching the user how label emails as spam or not spam
P = The fraction of email correctly classified as spam/not spam
In general, any machine learning problem can be assigned to one of two broad classifications: Supervised learning and Unsupervised learning.
Supervised learning
From the classical example, presented in the course also, let’s consider the problem of predicting the price of a house based on the size of the house.
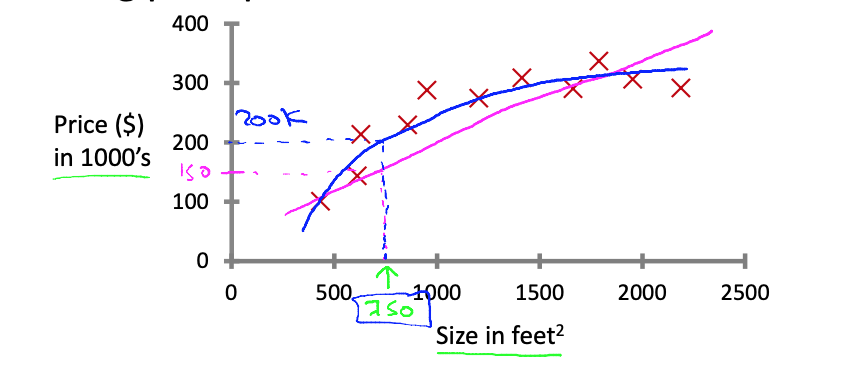
Note: The image is from the course.
In order to solve the problem you need a “function”, that can take the size of the house as input and outputs the predicted price.
Our function can be:
F(x) = p0 + p1*x
where:
- p0 and p1 are the “parameters” of our function
- x is the input, the size of the house
We already have a data set of collected values of X (house size) and the value of Y(the price of the house) and we can use that to learn to predict the price of the house.
But, before that, in order to find the optimal values for p0 and p1 we need a way to measure the error, a function that can measure how far the values predicted are from the actual values.
The error for one example is F(x) - Y and from this we can define the error of the whole data set (the cost function) to be average of sum of the squared difference.
J(p0, p1) = 1/2m * SUM(F(x) - Y)2)
We need to find the values of p0 and p1 where the error of the whole data set is minimum.
It turns out there is an algorithm that we can use in order to find the optimal values for p0 and p1 and is called “gradient descent”, and this algorithm is the base of all the machine learning that we have today. I won’t detail here how gradient descent works. In the course there is a dedicated section exceptionally well explained.
After we find the values of the p0 and p1 we can use it to predict the price of the house based on the size.
This is it. At very minimum this is machine learning, this is how all started.
In the course you will find everything you need to know about: how to choose the function, how to choose the cost function, how to use gradient descent to find the optimal parameter values, you will also learn about the tools that you can use to train (find the optimal values) and you will find about the neural networks, which are a different representation of the function.
Just for a fact the “ResNeXt-101–32x48d” neural network has 829 million parameters and is not the biggest.
Unsupervised learning
Unsupervised learning allows us to approach problems with little or no idea what our results should look like. We can derive structure from data where we don’t necessarily know the effect of the variables.
We can derive this structure by clustering the data based on relationships among the variables in the data.
With unsupervised learning there is no feedback based on the prediction results.
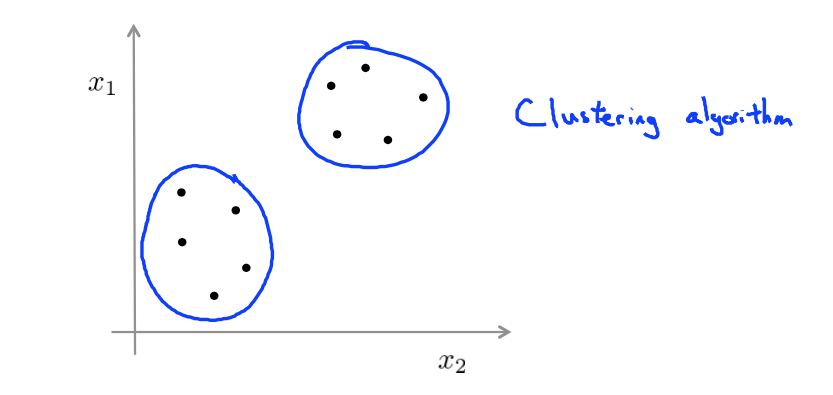
Given a data set one type of structure we might have an algorithm find is that it looks like this data set has points grouped into two separate clusters and so an algorithm that finds clusters like the ones.
The K-Means algorithm is by far the most popular, by far the most widely used clustering algorithm, and I will details briefly how this algorithm works.
K-Means is an iterative algorithm and it does two things:
- cluster assignment
- move centroid
For cluster assignment step we have to go through the data set and assign each point to a cluster depending whether it is closer to one of the centroid or another.
For move centroid step we going to calculate the mean of the location of all the points associated with each of cluster and we going to set the centroid at that location.
With the new centroids we will do again the cluster assignment followed by the movement of the centroids and we will continue to this this until the cluster centroids will not change any further.
This only a very light presentation of the “unsupervised learning” but on the course you will find a lot more about K-Means, PCA and some other unsupervised learning. Also you will have the chance to implement this algorithms yourself as part of the course assignment.
Conclusion
I personally learn a lot form this course and I think it worth all the time spent to finish the course and the programming assignments.